大家午安~本系列文章終於進入最後五天,我們也終於要開始認識現在最流行的機器學習方式-深度學習了。本來是計畫可以連實作一起分享的,但光是概念理解就已經夠要命了,所以接下來五天應該會以概念理解作為主軸來介紹深度學習的基礎跟一些模型。如果有餘裕的話再示範實作的部分。
想理解深度學習的話,我們要先從神經網路(Neural Network)開始了解。簡單說起來,神經網路就是模擬人類神經元運作的一種數學模型。下面這是人類神經細胞的示意圖(圖片來源):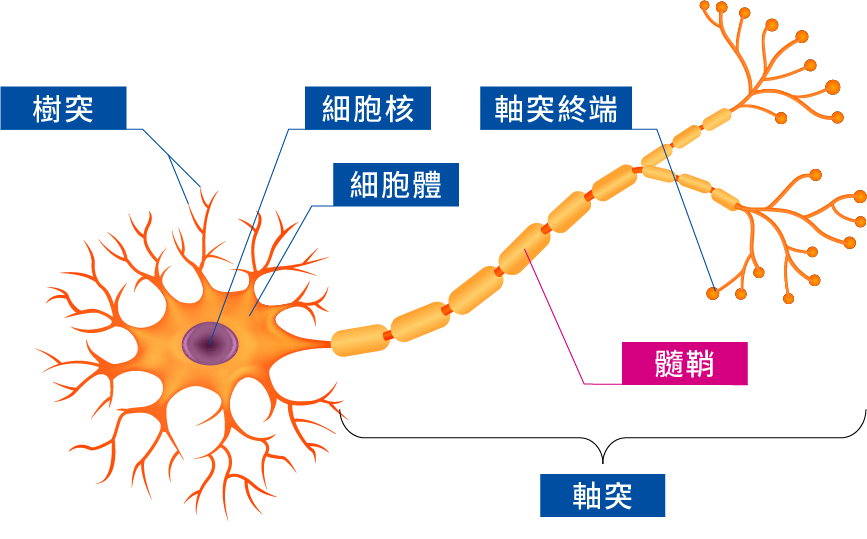
當有外部訊息要傳入細胞的時候,會透過樹突傳進來給神經元。神經元再根據傳進來的訊息種類決定要不要把這個訊息繼續傳下去,如果要的話就會透過軸突傳給末端的突觸(就是圖裡面末端圓圓的地方),而突觸連結著下一個神經細胞的樹突,所以這個訊息就被傳到下一個細胞了。
基本上神經網路裡面的神經元也可以分成這樣的三個部分,分別是輸入狀態(Input State)、隱藏狀態(Hidden State)、跟輸出狀態(Output state)。而從input state進到hidden state再到output state的過程主要可以分成下面三個步驟: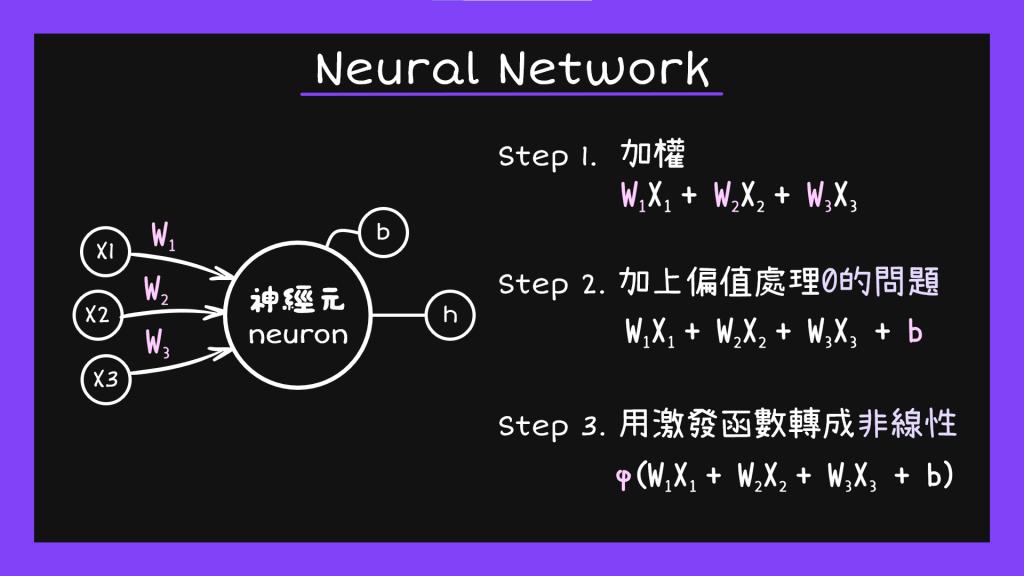
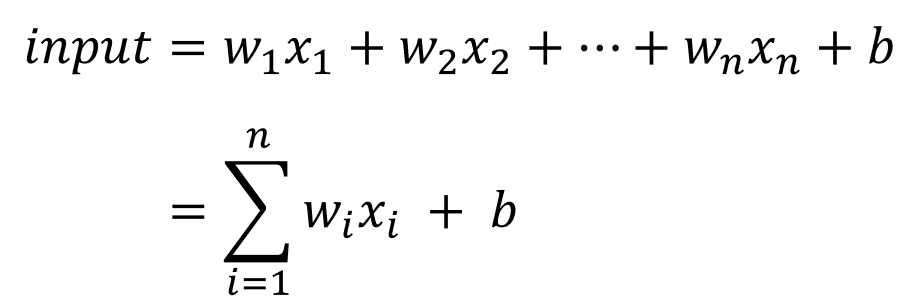
眼尖的人應該已經發現了,啊這不就直線公式y=ax+b嗎?沒錯,我們可以把input state在做的事情當成把資料變成一條線。問題是我們都知道現實生活根本沒那麼美好,不可能所有資料分布都呈線性分布,不然我們用logistic regression跟linear regression就可以解決問題了,哪還需要這麼多有的沒的。所以接著我們就要把這條線交給hidden state處理。
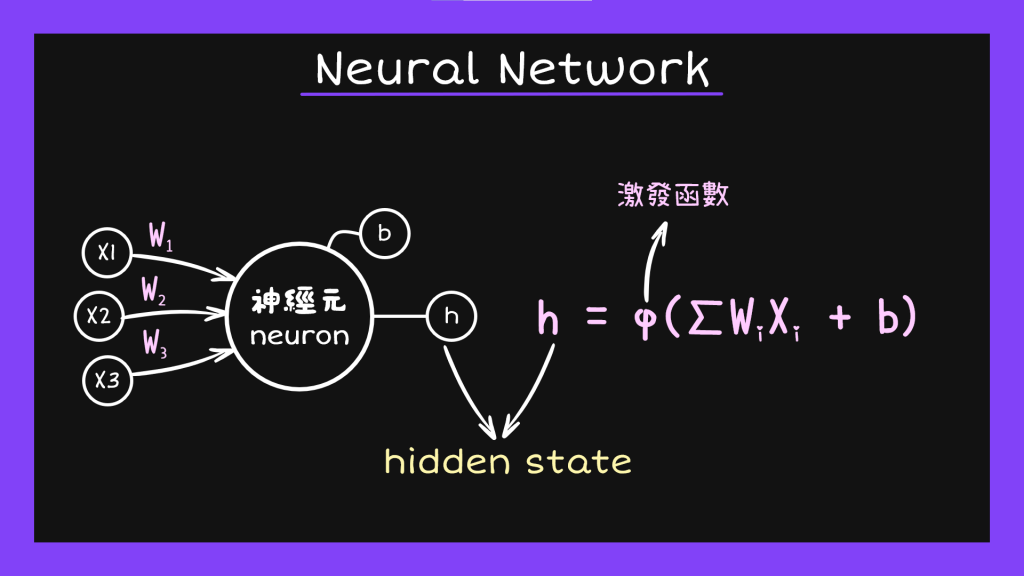
傳統的說法裡面有三種比較常見的激發函數:S型函數(Sigmoid function)、高斯函數(Gaussian function)跟ReLU。因為前兩個在算法上都會產生問題,讓訓練結果變差,所以現在比較常用的是ReLU函數。因為今天的重點是神經網路跟深度學習的概念,這邊就不多做說明。
線性函數經過轉換之後我們就能根據任務得出需要的值,但是通常都會希望出來的東西可以是像機率這種比較容易理解的數字,所以我們常常會在從hidden state要傳送資料給output state的時候再用sigmoid function轉換成0到1之間的數字。以上就是一個神經元運作的完整過程。我們可以把這些神經元想像成一個一個的特徵,因為我們做模型訓練的時候一定不只一個特徵,把這些特徵的作業過程一個一個列出來就會形成像下面這樣的網路系統,所以才會把這種模型叫做神經網路(Neural Network)。然後因為每一個地方都不只一個神經元在工作,所以神經網路的第一個部分就叫做輸入層(input layer),中間激發函數工作的地方就叫做隱藏層(hidden layer),最後輸出的地方則是輸出層(output layer)。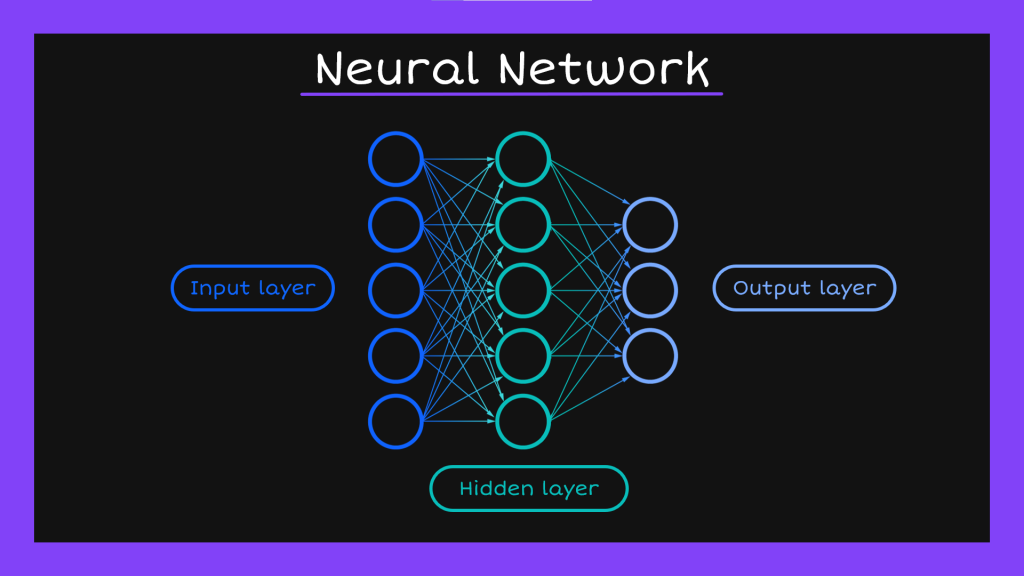
以上是最簡單的神經網路系統,而如果我們多加幾層hidden layer變成下面這樣,就會變成深度神經網路(Deep Neural Network)。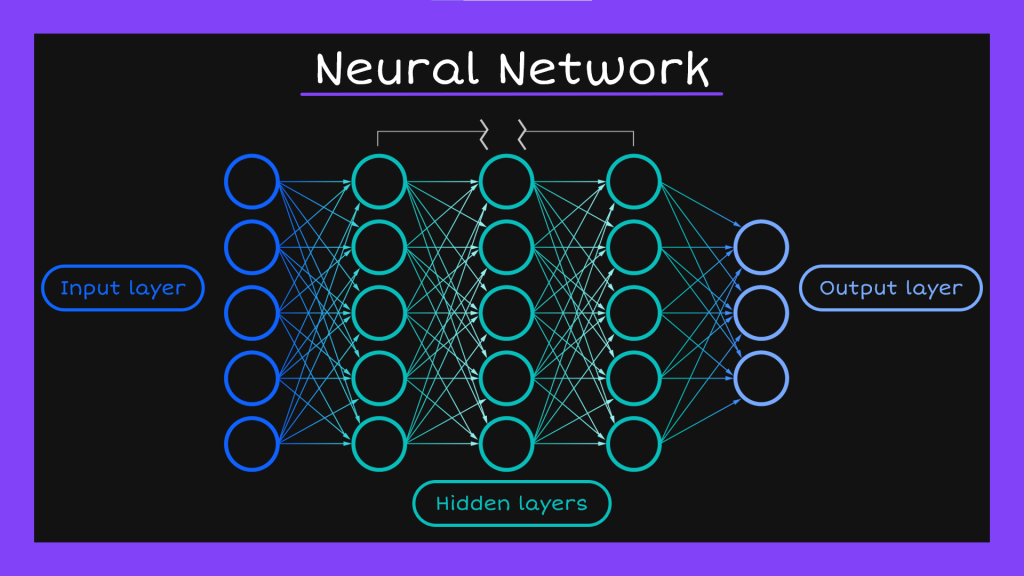
為了解釋這兩者的不同,這邊要用火影忍者的劇情來說明。當初鳴人想學查克拉性質變化的時候,大家都告訴他一般忍者需要好幾年的時間練成。但是鳴人要找到佐助還要打敗曉,根本等不了那麼久。所以卡卡西想了一個妙招,就是讓他用多重影分身之術來學查克拉的性質變化。因為影分身做的事情在分身消失之後都會變回經驗回到本體身上,也就是別人五個小時的學習經驗會等同於鳴人變出四個分身學習一個小時的經驗。鳴人就用這個方法花了不到一個月的時間練成了風遁手裡劍。
一般神經網路就像是交代鳴人自己不用忍術去學一件事,深度神經網路則像是讓他用影分身之術學一件事,每多一個hidden layer就像多一個影分身一樣,可以讓我們模型的學習成效變高。
這邊需要注意的是,所謂深度學習跟深度神經網路的「深度」,修飾的是不一樣的東西。剛剛提到深度神經網路指的是不只一層的神經網路,而深度學習則是指擁有很多特徵,也就是很多神經元的神經網路。他跟我們之前提到的監督式學習不同。監督式學習的特徵萃取需要透過人工進行,非常耗時。但深度學習的特徵萃取完全靠模型自己計算,所以雖然特徵更多了,卻也更節省了人力還大幅提高了模型表現。這就是為什麼現在機器學習的領域當中,深度學習會這麼受歡迎的原因。
今天針對神經網路跟深度學習的簡介就到這邊告一個段落,有任何問題都可以在下面留言回應喔~接下來會針對跟NLP相關的深度學習模型進行介紹,那就明天見了~

